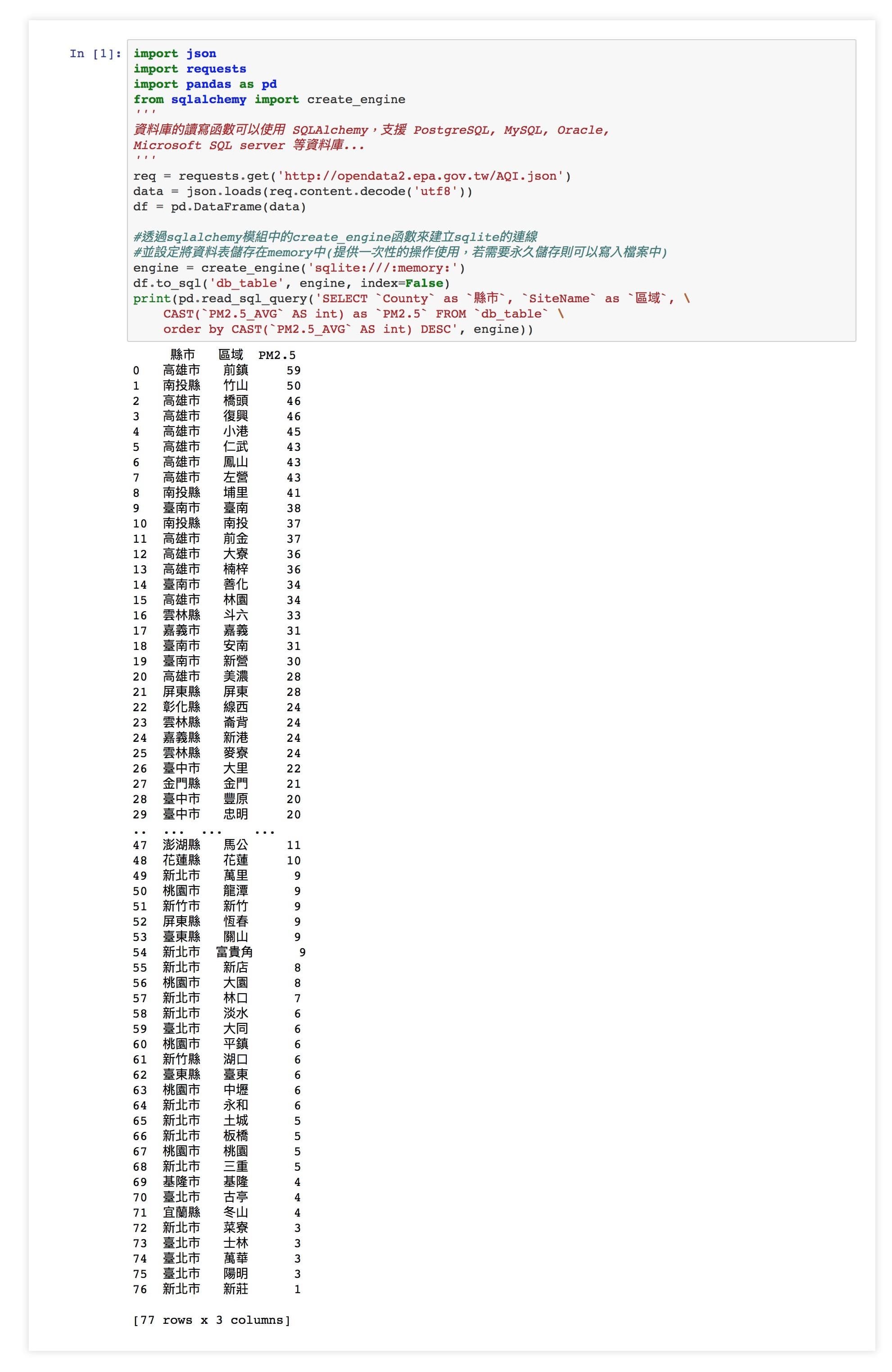
PEP 8 介紹
PEP8 是 Python 社群共通的風格指南,一開始是 Python 之父 Guido van Rossum 自己的撰碼風格,慢慢後來演變至今,目的在於幫助開發者寫出可讀性高且風格一致的程式。許多開源計畫,例如 Django 、 OpenStack等都是以 PEP8 為基礎再加上自己的風格建議。
程式碼編排 (Code lay-out)
這邊列出PEP8裡面的重點,有興趣可以直接看官方原文的文件會更清楚一些。
縮排 (Indentation)
每層縮排使用 4 個空格
斷行風格
正確:
# 斷行首字母與開頭的括號垂直對齊.
foo = long_function_name(var_one, var_two,
var_three, var_four)
# 垂直縮排,首行不能有參數.
def long_function_name(
var_one, var_two, var_three,
var_four):
print(var_one)
# 垂直縮排,後面還有其它代碼時,需要添加一層額外的縮排加以區別:
foo = long_function_name(
var_one, var_two,
var_three, var_four)
錯誤:
# 垂直縮排方式首行不能有引數
foo = long_function_name(var_one, var_two,
var_three, var_four)
# 垂直縮排,首行不能有參數; 後面還有其它代碼部分時,斷行要添加一層縮進,使其與其它代碼部分能區別開來
def long_function_name(
var_one, var_two, var_three,
var_four):
print(var_one)
if 條件斷行
if ( 剛好有 4 個字符,相當於一層縮排。
對於 if 條件斷行,以下幾種風格都可以:
沒有額外的縮排
if (this_is_one_thing and
that_is_another_thing):
do_something()
添加註釋加以區分
# Add a comment, which will provide some distinction in editors
# supporting syntax highlighting.
if (this_is_one_thing and
that_is_another_thing):
# Since both conditions are true, we can frobnicate.
do_something()
添加額外的縮排加以區分
# Add some extra indentation on the conditional continuation line.
if (this_is_one_thing
and that_is_another_thing):
do_something()
多行的括號
括號結束符與最後行的首字符對齊,如:
my_list = [
1, 2, 3,
4, 5, 6,
]
result = some_function_that_takes_arguments(
'a', 'b', 'c',
'd', 'e', 'f',
)
括號結束符與首行的首字符對齊, 如:
my_list = [
1, 2, 3,
4, 5, 6,
]
result = some_function_that_takes_arguments(
'a', 'b', 'c',
'd', 'e', 'f',
)
上面兩種排版的方式都可以
使用Tab還是空格縮排
用空格
每行最長長度
所有行都不超過 80 個字符
限制編輯器視窗的寬度,使能並排同時打開多個文件。
設置編輯器寬度(set width to 80),來避免 wrapping
對於較少結構限制的長文本(如 docstrings 或註釋),行長應限制為 72 個字符。
如果團隊成員都同意使用長行,則可以將行長增加到不超過 100 個字符,但是 docstrings 和註釋還必須為 72 個字符。
有括號的長行可以用 implicit continuation 來斷行,其它的可以用 \ 來斷行,如:
with open('/path/to/some/file/you/want/to/read') as file_1, \
open('/path/to/some/file/being/written', 'w') as file_2:
file_2.write(file_1.read())
操作符要和操作數在一起
# 推薦的正確的風格,這樣很容易將操作符與操作數匹配:
income = (gross_wages
+ taxable_interest
+ (dividends - qualified_dividends)
- ira_deduction
- student_loan_interest)
# 這種風格現今已不推薦使用了:
income = (gross_wages +
taxable_interest +
(dividends - qualified_dividends) -
ira_deduction -
student_loan_interest)
空行分隔
模組中最頂層的函數和類定義都要用兩行空行分隔
類別中的方法定義用單行分隔
要把一組相關的函數分組,可以用一些額外的空行
函數中的邏輯區塊可以加空行來分隔
原始碼的編碼
Python 核心模組文件的編碼都必須用 UTF-8(Python2 是 ASCII)。
使用默認的編碼時(Python3: UTF-8,Python2: ASCII),不能使用編碼聲明
標準庫中,只有測試、作者名才能使用非默認的編碼,其它情況下的非 ASCII 字符用 \x, \u, \u, \N 表示法表示。
Import
每行 import 只導入一個模組:
# 正確:
import os
import sys
# 錯誤:
import sys, os
# 正確:同一模組中的內容可以在同一行導入
from subprocess import Popen, PIPE
import 語句要在文件的前面,在模組註釋及 docstrings 之後,在模組全域變數和常數定義之前。
import 分組及導入順序,每個分組之間用一行空行分隔 1. 標準庫 2. 相關第三方庫 3. 本地應用/庫的特殊導入
推薦使用絕對導入,如:
import mypkg.sibling
from mypkg import sibling
from mypkg.sibling import example
在比較覆雜的套件組成中,也可以用顯式的相對導入,如:
from . import sibling
from .sibling import example
從一個模塊中導入一個類別時,要顯示拼寫出類別名,如:
from myclass import MyClass
from foo.bar.yourclass import YourClass
如果與本地名稱衝突,可以先導入模組:
import myclass
import foo.bar.yourclass
然後使用:"myclass.MyClass" 和 “foo.bar.yourclass.YourClass"。
應該避免使用 from <module> import *
模組層級的特殊名稱(如__all__)的位置:
必須在模組的 docstrings 或註釋之後,但在任何的 import 語句之前。from __future__ 比較特殊,Python 強制該語句必須在 docstrings 或註釋之後,因此風格如下:
"""This is the example module.
This module does stuff.
"""
from __future__ import barry_as_FLUFL
__all__ = ['a', 'b', 'c']
__version__ = '0.1'
__author__ = 'Cardinal Biggles'
import os
import sys
字符引號 (String Quotes)
單引號和雙引號的功能是等同的。
對於多行字符串,應該用雙引號字符形式的三引號""",以便與 PEP257 中的 docstrings 規範兼容
表達式和語句中的空格 (Whitespace in Expressions and Statements)
()、[]、{} 等括號內不要多餘的空格,如:
# 正確:
spam(ham[1], {eggs: 2})
# 錯誤:
spam( ham[ 1 ], { eggs: 2 } )
,、;、: 之前不要有空格,如:
# 正確:
if x == 4: print x, y; x, y = y, x
# 錯誤:
if x == 4 : print x , y ; x , y = y , x
在 slice 語句中的 :實際上是一個二元操作符,因此其兩側的空格數必須相同; 但當無 slice 參數時,兩側的空格可以都省略,如:
# 以下是正確的風格:
ham[1:9], ham[1:9:3], ham[:9:3], ham[1::3], ham[1:9:]
ham[lower:upper], ham[lower:upper:], ham[lower::step]
ham[lower+offset : upper+offset]
ham[: upper_fn(x) : step_fn(x)], ham[:: step_fn(x)]
ham[lower + offset : upper + offset]
# 以下是錯誤的風格:
ham[lower + offset:upper + offset]
ham[1: 9], ham[1 :9], ham[1:9 :3]
ham[lower : : upper]
ham[ : upper]
函數調用的 () 及索引的 [] 前不要加空格,如:
# 正確風格:
spam(1)
dct[‘key’] = lst[index]
# 錯誤風格:
spam (1)
dct [‘key’] = lst [index]
不要在賦值語句中加入額外的空格來對齊,如:
# 正確的風格:
x = 1
y = 2
long_variable = 3
# 錯誤的風格:
x = 1
y = 2
long_variable = 3
其它推薦風格
任何行的行尾都不要有空白符。
在二元操作符號兩側一般都要加一個空格,一般的二元操作符號如:
賦值: =, +=, -=
比較:==, <, >, !=, <>, <=, >=, in, not in, is, is not
布林操作: and, or, not
在分優先級的表達式中,在最低優先級的操作符兩側加一個空格,但至多只能加一個空格,如:
# 正確的風格:
x = x*2 – 1
hypot2 = x*x + y*y
c = (a+b) * (a-b)
# 錯誤的風格:
x = x * 2 – 1
hypot2 = x * x + y * y
c = (a + b) * (a – b)
在關鍵字參數和默認參數值中的 = 兩側不要加空格,如:
# 正確的風格:
def complex(real, imag=0.0):
return magic(r=real, i=imag)
錯誤的風格:
def complex(real, imag = 0.0):
return magic(r = real, i = imag)
函數註解中的 : 前不要加空格,這符合 : 的常規風格,但是 -> 兩側要加空格,如:
# 正確的風格:
def munge(input: AnyStr): …
def munge() -> AnyStr: …
# 錯誤的風格:
def munge(input:AnyStr): …
def munge()->PosInt: …
參數註解中,如果註解的參數有默認值,指定默認值的 = 兩側要加空格,如:
# 正確的風格:
def munge(sep: AnyStr = None): …
def munge(input: AnyStr, sep: AnyStr = None, limit=1000): …
# 錯誤的風格:
def munge(input: AnyStr=None): …
def munge(input: AnyStr, limit = 1000): …
不要將多條語句組合在一行中,如:
# 正確的風格:
if foo == ‘blah’:
do_blah_thing()
do_one()
do_two()
do_three()
# 錯誤風格:
if foo == ‘blah’: do_blah_thing()
do_one(); do_two(); do_three()
# 如果 if/for/while 區塊內的程式碼很少,組合在一行有時還是可以接受的
# 但是不推薦,如:
if foo == ‘blah’: do_blah_thing()
for x in lst: total += x
while t < 10: t = delay()
# 但是在有多段語句時,絕對不能這樣,如:
if foo == ‘blah’: do_blah_thing()
else: do_non_blah_thing()
try: something()
finally: cleanup()
do_one(); do_two(); do_three(long, argument,
list, like, this)
if foo == ‘blah’: one(); two(); three()
註解 (Comments)
註解內容必須要和程式碼相關!
註解應該是完整的語句,首字母一般大寫(英文),一般要有句號。
註解很短時句號可以省略。
區塊註解一般由多個段落組成。用英文寫註解
區塊註解 (Block Comments)
每行用 # 及一個空格開始,如 #
段落用一個只有 # 的行分隔
行內註解 (Inline Comments)
註解與語句內容至少用兩個空格分開,註解用 # 加一個空格開始
# 不要像下面這樣,註解內容沒有必要
x = x + 1 # Increment x
# 但是有時,如下面的註解會很有用
x = x + 1 # Compensate for border
文件字串 (Documentation Strings)
公開的模組、函數、類及方法都應該有文件字串,而非公開的方法可以用註解來代替,且註解放置在 def 行之後。
多行的文件字串,結束符號要自成一行,如:
"""Return a foobang
Optional plotz says to frobnicate the bizbaz first.
"""
單行的文件字串,結束符號和內容放在同一行
命名 (Naming Conventions)
沒有推薦的風格,但是別人要能從你的程式碼中看出你用的是什麽風格,常用的風格如下:
- b 單個小寫字母
- B 單個大寫字母
- lowercase
- lower_case_with_underscores
- UPPERCASE
- UPPER_CASE_WITH_UNDERSCORES
- CapitalizedWords, 這種風格中,對於縮寫詞應全部用大寫,如
- HTTPServerError 比 HttpServerError 好
- mixedCase
Capitalized_Words_With_Underscores,這個太醜,不要用這種!
- st_mode、st_mtime 等前綴,一般是系統接口返回,如果自己寫的程式碼不推薦用這種
- _single_leading_underscore : 弱 “內部使用” 指示器,這種對象用 from M import * 不會被導入
- single_trailing_underscore_ : 可以用來和 Python 關鍵詞進行區分,如 Tkinter.Toplevel(master, class_=’ClassName’)
- __double_leading_underscore : 命名一個類屬性時,可以進行命名矯正,例如 class FooBar 內的 __boo 會變成 _FooBar__boo
- double_leading_and_trailing_underscore : “magic” 對象,不要自己發明這種對象
命名習慣 (Prescriptive: Naming Conventions)
- 不用單個 l, O, I 等這樣的單個字符來命名,它們與數字1,0不好區分
- 套件名和模組名:全部用小寫,必要時可用 _,但不推薦,C/C++ 的擴展模組,如果其對應有 Python 版本,那麽 C/C++ 擴展模組名前加 _
- 類別名:用 CapWords 風格
- 異常名:用 CapWords 風格,一般應該有 Error 後綴
- 全域變數名:能用 from M import * 導入的變數全部放在 __all__ 中,或者全域變數用 _ 做前綴
- 函數名:應該用全部用小寫,單詞間可以用 _ 分隔,如 my_func,不推薦用 mixedCase 風格
- 函數和方法的參數:實例方法的第一個參數用 self, 類別方法的第一個參數用 cls,如果參數與關鍵字衝突,在參數名後加 _ 後綴,如 class_
- 實例變數和方法: 用小寫字符和 _, 非公開的實例變數和方法用一個 _ 做前綴; 避免與子類別中的名字衝突,類的變數可用兩個 _ 作前綴,例如 class FooBar 內的 __boo 會變成只能通過 FooBar._FooBar__boo 讀取
- 常數:全部大寫,可用 _ 分隔,如 MAX_OVERFLOW、TOTAL
推薦的程式撰寫方式 (Programming Recommendations)
字符串連接不要用 a += b 或者 a = a + b, 用 “.join(), 後者性能更好。跟 None 的比較用 is 和 is not,不要用 ==,如果你想判斷 if x is not None, 不要縮寫成 if x 使用 if foo is not None,而不是 if not foo is None,前者更加易讀
如果要實現序列比較操作的話,應將 6 個操作(__eq__ , __ne__ , __lt__ , __le__ , __gt__ , __ge__)全部實現,可以借助 functools.total_ordering() 修飾器來減少工作量
將函數保存在一個變數中應該用 def f(x): return 2*x, 而非 f = lambda x: 2*x,後者不利於調試
自定義的異常類應該繼承至 Exception 類,而非 BaseException 類。Python 2 中拋出異常用 raise ValueError(‘message’),而非 raise ValueRoor, ‘message’
盡量可以的指明異常名,如:
try:
import platform_specific_module
except ImportError:
platform_specific_module = None
避免使用無異常名的 except: 語句,它會捕獲全部的異常(如 Ctrl C)。
將異常綁定到名字的方法:
try:
process_data()
except Exception as exc:
raise DataProcessingFailedError(str(exc))
try: 中的語句要盡量減少,如:
# 正確的寫法:
try:
value = collection[key]
except KeyError:
return key_not_found(key)
else:
return handle_value(value)
# 錯誤的寫法
try:
# Too broad!
return handle_value(collection[key])
except KeyError:
# Will also catch KeyError raised by handle_value()
return key_not_found(key)
如果資源只適用於某個代碼段內,使用 with 或 try/finally 來確保能進行清理工作
上下文管理器應用通過一個單獨的函數或方法來呼叫,如:
# 正確的做法:
with conn.begin_transaction():
do_stuff_in_transaction(conn)
# 錯誤的做法:
with conn:
do_stuff_in_transaction(conn)
return 語句應該一致,如:
# 正確的做法:
def foo(x):
if x &amp;amp;amp;amp;amp;amp;amp;amp;gt;= 0:
return math.sqrt(x)
else:
return None
def bar(x):
if x &amp;amp;amp;amp;amp;amp;amp;amp;lt; 0:
return None
return math.sqrt(x)
# 錯誤的做法:
def foo(x):
if x &amp;amp;amp;amp;amp;amp;amp;amp;gt;= 0:
return math.sqrt(x)
def bar(x):
if x &amp;amp;amp;amp;amp;amp;amp;amp;lt; 0:
return
return math.sqrt(x)
使用字符串的方法,而不是用 string 模組中的方法
使用 “.startswith() 和 “.endswidth() 而不用 slicing 來檢查前綴和後綴:
# 正確:
if foo.startswith(‘bar’):
# 錯誤:
if foo[:3] == ‘bar’:
判斷對象的類型用 isinstance 而不直接 type 比較,如:
# 正確:
if isinstance(obj, int):
# 錯誤:
if type(obj) is type(1):
對序列是否空的判斷不用 len,如:
# 正確:
if not seq:
if seq:
# 錯誤:
if len(seq):
if not len(seq):
布林值的比較:
# 正確:
if greeting:
# 不要這樣:
if greeting == True:
# 這樣更不行:
if greeting is True:
參考資料:
PEP 8 — Style Guide for Python Code