依據行政院人事室規定,2/27-3/1為和平紀念日連續假期, 故此段期間為國定假日,停課一次
「Chifu」的全部文章
受保護的文章:Python 340期 作業繳交
受保護的文章:Python 337期 作業繳交
受保護的文章:Python 336期 作業繳交
受保護的文章:Python 335期 作業繳交
受保護的文章:Python 330期 作業繳交
Python 326期 4/2 清明連假,停課一次
依據行政院人事室規定,4/2-4/5為清明連續假期,
故此段期間為國定假日,不需到班上課。
Python 320期 9/30 停課一次
9/30 台北市停班停課,所以當天課程將暫停一次,課程會順延至 10/24 為最後一堂上課
Python IDEs 常見的整合開發環境介紹
Python IDEs
俗語說 ”工欲善其事,必先利其器 ” 。
所以在撰寫 python 程式時,挑選好的開發工具 Python IDEs 是蠻重要的一件事情。其實 Python官方的安裝包裡面含有 IDLE,已經是個麻雀雖小五臟俱全的IDE了,對於初學的人其實已經蠻夠用了。
但如果能了解有哪些不錯的IDEs,對於我們未來撰寫功能更複雜的大型專案,或是有資料科學領域上的需求就能使用更方便、更合適的工具,對於開發效率上也能有所提升。
以下介紹一些 Python 常見的 IDEs (Integrated Development Environment):
Spyder
如果有安裝過 Anaconda distribution 版本的話,應該會知道Spyder。Spyder整合了NumPy,SciPy,Matplotlib 與 IPython,以及其他開源軟體。
- 編輯器:支援多語言,具有函式和類檢視器,代碼分析特性(pyflakes 和 pylint 獲得了支援),代碼補全,水平與垂直視窗的分離,直接跳入定義等等。
- 互動埠: Python 或 IPython 埠都在工作區可以調整和使用。支援對編輯器里的代碼直接偵錯。此外整合了 Matplotlib 的圖表顯示。
- 文件瀏覽器:在編輯器或埠中顯示任意類或函式呼叫的文件。
- 可變的瀏覽窗口:在檔案的執行過程中可以建立可變的瀏覽窗口。同時也可以對其進行編輯。
- 在檔案中尋找:支援正規表示式與 Mercurial 倉庫
- 檔案瀏覽器
- 歷史記錄
Jupyter Notebook
![]()
與Spyder一樣,被包含在 Anaconda distribution 的版本之中,若要獨立使用 pip 安裝亦可。
透過網頁介面,可以將程式碼寫在不同的 Cell (區塊) 之中,並且分段落執行,已執行過的程片段會存在記憶體中,所以對於調整參數或是做測試來說,相當的方便,比如有時候想要看變數的值,直接開個 Cell 印出來看就好了
- 支援超過 40 種程式語言,比如 Python、R,、Julia 與 Scala
- 可以透過 email、Dropbox、GitHub 或是 Jupyter Notebook Viewer 與他人分享 Notebook
- 可以顯示多媒體資源,比如圖片、影片、LaTeX 甚至是JavaScript,也可以做 realtime 的資料視覺化
PS1. 微軟的 Azure Notebooks 就是使用 Jupyter Notebook。目前提供免費的線上開發服務,若還沒安裝本機端 IDE,但是想先體驗看看 Jupyter Notebook 也可以直接登入用看看。
PS2. 之前有寫一篇使用 Python 擷取 AQI 空氣品質資料的範例,就是在 Azure Notebooks 這個服務上寫的。 範例程式
PyCharm
![]()
https://www.jetbrains.com/pycharm/
PyCharm是由捷克公司JetBrains開發。提供代碼分析、圖形化調試器,集成測試器、集成版本控制系統(Vcs),並支持使用Django進行網頁開發。
是一套功能非常完善也強大的跨平台開發的環境。
是一套功能非常完善也強大的跨平台開發的環境。
主要功能:
- 代碼分析與輔助功能,擁有補全代碼、高亮語法和錯誤提示;
- 項目和代碼導航:專門的項目視圖,文件結構視圖和和文件、類、方法和用例的快速跳轉;
- 重構:包括重新命名,提取方法,引入變量,引入常量、pull,push等;
- 支持網絡框架: Django, web2py 和 Flask;
- 集成Python 調試器;
- 集成單元測試,按行覆蓋代碼;
- Google App Engine下的Python開發;
- 集成版本控制系統:為Mercurial, Git, Subversion, Perforce 和 CVS提供統一的用戶界面,擁有修改以及合併功能。
PyDev

PyDev 是 Eclipse 的 插件 plugin,若有使用過 Eclipse寫過 Java 或是開發過 Android 很習慣在Eclipse上面開發程式的話,
可以考慮安裝 PyDev 來開發 Python 程式,當然其功能也是相當完整。
Visual Studio
微軟出的 Visual Studio 應該非常多人聽過也用過,也支援Python的程式語言開發
若有使用過 Visual Studio 開發過 C#、VB.NET、ASP.NET 等相關微軟平台上的程式專案開發的話,那麼在這個介面上開發 Python 程式或許也是個不錯的選擇。
結語
當然還有非常多不錯的 Python IDEs 沒有列舉出來,待之後有時間再補上來。
Pandas+SQL-空氣品質資料擷取
Pandas+SQL 操作 – 前言
Pandas+SQL 的操作範例,本篇文章以政府開放資料平台中的 空氣品質指標(AQI) 為資料來源,展示了如何使用 pandas 搭配 SQL 語法 來做資料搜尋,對於已經有 SQL 語法操作基礎的人,可以用之前學過的 SQL 語法快速的搜尋並篩選出所需要的資料,提供大家參考。
Pandas 簡介
Pandas 是 python 的一個數據分析模組庫,於 2009 年底開源出來,提供高效能、簡易使用的資料格式 (Data Frame) 讓使用者可以快速操作及分析資料,主要特色描述如下:
- 在異質數據的讀取、轉換和處理上,讓分析人員更容易處理,例如:從列欄試算表中找到想要的值。
- Pandas 提供兩種主要的資料結構,Series 與 DataFrame。
- Series: 用來處理時間序列相關的資料(如感測器資料等),主要為建立索引的一維陣列。
- DataFrame: 用來處理結構化(Table like)的資料,有列索引與欄標籤的二維資料集,例如:關聯式資料庫、 CSV 等等。
- 透過載入至 Pandas 的資料結構物件後,透過結構化物件所提供的方法,快速地資料前處理。例如:資料補值,空值去除或取代等。
- 更多的輸入來源及輸出整合性,例如:可以從資料庫讀取資料進入 Dataframe ,也可將處理完的資料存回資料庫。
本篇文章就是使用 DataFrame 搭配關連式資料庫,使用 SQL 語法進行資料查詢篩選,而未來有時間再整理更多其他 Pandas 相關的應用範例。
安裝 Pandas
Python 安裝方式一樣都是透過 pip install 即可完成安裝,語法如下:
pip install pandas
其他介紹可以參考 官方網站
JSON
JSON(JavaScript Object Notation)是一種由道格拉斯·克羅克福特構想設計、輕量級的資料交換語言,以文字為基礎,且易於讓人閱讀。儘管 JSON 是 Javascript 的一個子集,但 JSON 是獨立於語言的文字格式,並且採用了類似於 C語言 家族的一些習慣。此種格式與XML格式常被用於API的資料回傳格式。本篇文章的程式碼範例就是以 JSON 格式的內容為資料的輸入來源。
範例程式碼
此範例程式主要流程大致為:
- 透過 requests 呼叫政府公開資料的 API 得到空氣品質指標的資料( JSON 格式)
- 透過 json.loads 函數將資料讀入
- 使用 pandas DataFrame 產生出資料框
- 透過 sqlalchemy 模組中的 create_engine 函數來建立 sqlite 的連線 ,並設定將資料表儲存在 memory 中(提供一次性的操作使用,若需要永久儲存則可以寫入檔案中)
- 使用 SQL 語法作取出特定的欄位(縣市、區域、平均 PM2.5 值)並以 PM2.5 的值由大至小排序。
import json
import requests
import pandas as pd
'''
資料庫的讀寫函數可以使用 SQLAlchemy,支援 PostgreSQL, MySQL, Oracle,
Microsoft SQL server 等資料庫...
'''
from sqlalchemy import create_engine
req = requests.get('http://opendata2.epa.gov.tw/AQI.json')
data = json.loads(req.content.decode('utf8'))
df = pd.DataFrame(data)
#透過sqlalchemy模組中的create_engine函數來建立sqlite的連線
#並設定將資料表儲存在memory中(提供一次性的操作使用,若需要永久儲存則可以寫入檔案中)
engine = create_engine('sqlite:///:memory:')
df.to_sql('db_table', engine, index=False)
print(pd.read_sql_query('SELECT `County` as `縣市`, `SiteName` as `區域`, \
CAST(`PM2.5_AVG` AS int) as `PM2.5` FROM `db_table` \
order by CAST(`PM2.5_AVG` AS int) ASC', engine))
點我觀看執行範例 (使用 Microsoft Azure Notebooks )
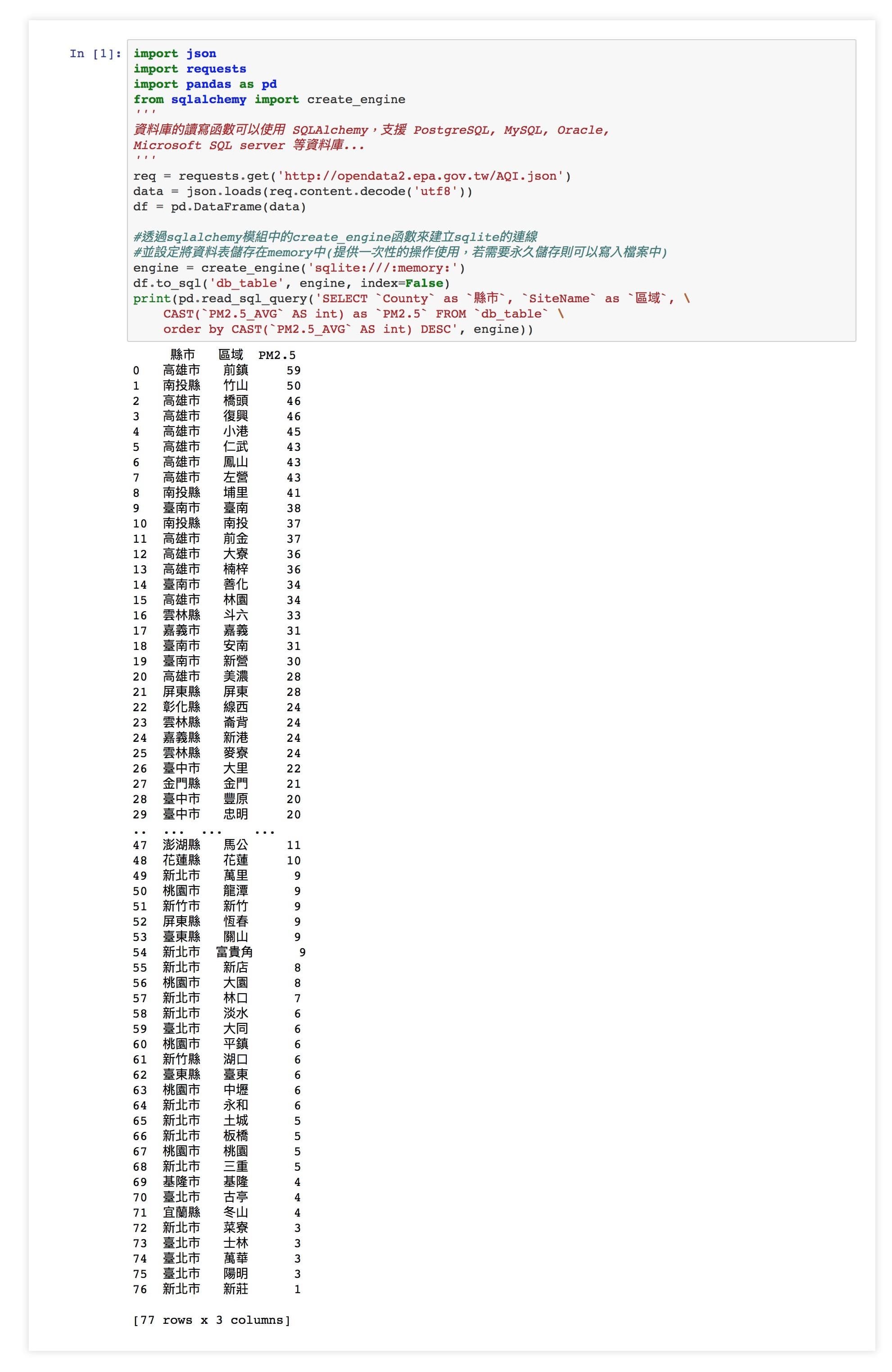
若有其他想法,例如:想知道哪個縣市的整體平均空氣品質較差就可以在 SQL 語法中使用 GROUP BY 語法,對於 SQL 語法熟悉的話就能輕易地藉由改變查詢的語法來獲得想查詢 / 篩選的資料。
PS. 對於Python語法上有疑問可以參考課程投影片